前言:这个是我自己老板参与的论文,发表在ASPLOS 20上,之后可能要做的东西和这个思路有一些关联,有必要读下。存算分离是解决scalability的大趋势,在网络带宽不再是瓶颈的时代,提供了存储和计算分别扩缩容的能力。文章聚焦到LSM上,把compaction作为算的部分,做了remote compaction的设计。
TL;DR版
本文通过加了一次disk pool设计的共享文件系统,实现了存储池化和存算分离。具体到LSM数据库上,通过存储池化来利用空闲磁盘I/O带宽,并基于池化的存储,按照存算分离思想将Compaction的过程放到CPU空闲的机器,以此提高Skew时load balance的效果,最终提高整体性能。
背景
使用RocksDB为首的LSM,在分布式场景下,一般会将数据shard到多个机器上,然后rocksdb落盘到本地(shared-nothing,MPP)。这种方式的问题是,
- 如果skew,需要reshard(比如分裂?),带来数据从一台机器上到另一台上潜移的成本,也会对性能有一些影响。
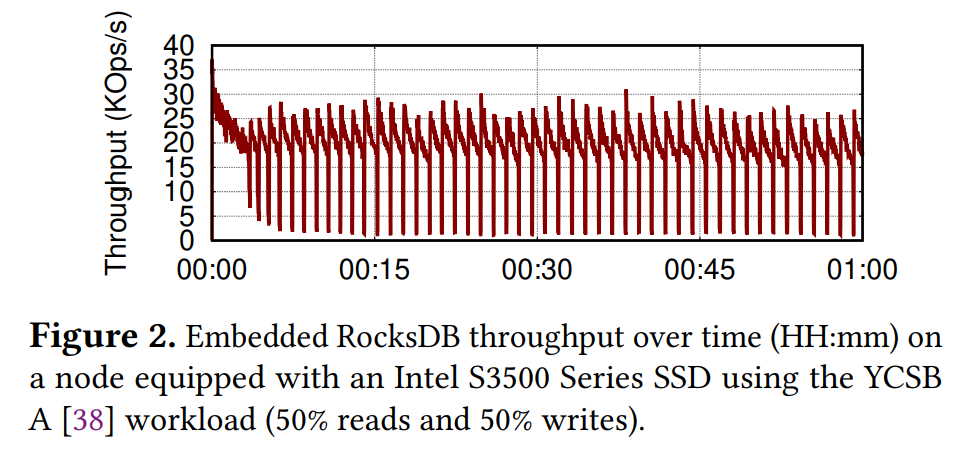
- 后台操作,比如Compaction和Flushing会有I/O和CPU的占用。导致整体性能不稳定(尤其是有range query的时候)(参见下图)。

Hailstorm本质上是个轻量文件系统,专门用来解决LSM数据库load balance和资源利用率的问题。使用Hailstorm,数据库可以实现存储和计算分别scale的功能。
- 对于storage的scaling,Hailstorm将一个机架(rack)上的磁盘池化,所有DB的LSM engine都可以共享磁盘贷款。上**层的数据会分block(1MB,extra information:rocksdb的单个sstable文件大小一般是64MB)**均匀落到各个磁盘上。保证磁盘的充分利用。
- 对于CPU的scaling,让其他机器做compaction,降低热点机器CPU占用。
实验证明,在skewed的测试集上,tail latecny明显降低,吞吐也有所提高(尤其是scan类型的)。
设计
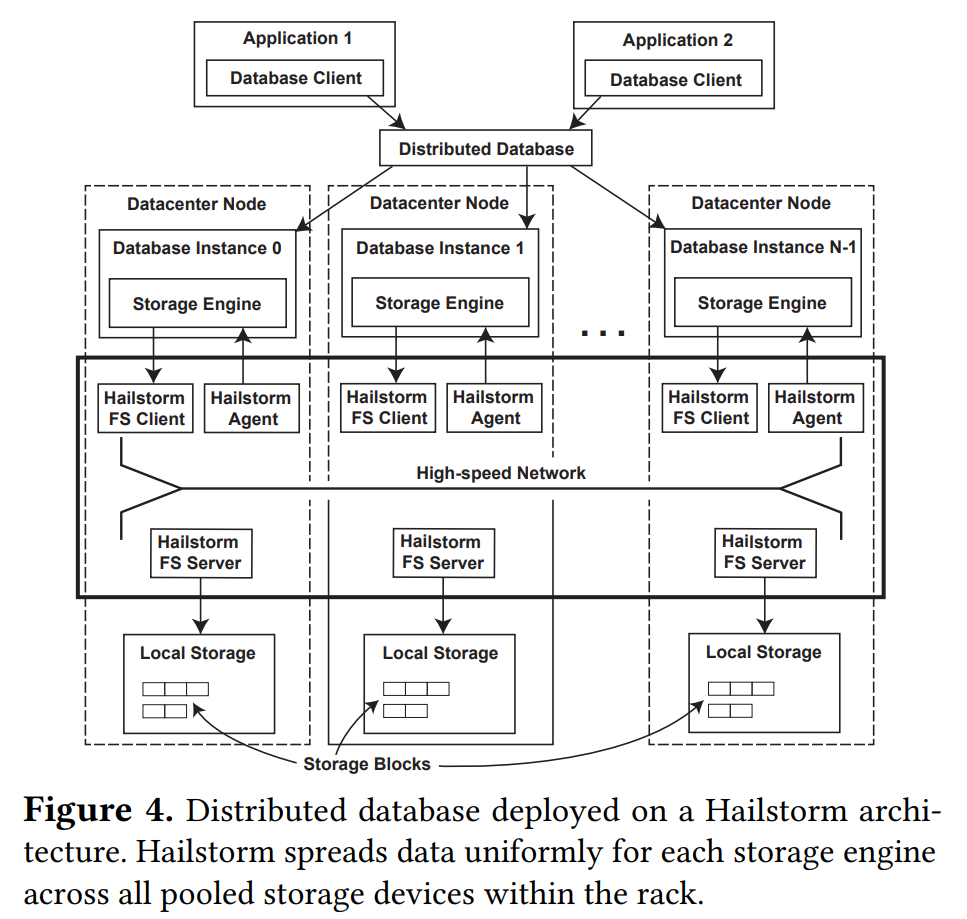
基于Hailstorm的数据库架构可以参看上图。设计时主要参考的原则是:
- 存算分离
- 存储池化
- 通过加一层redistribution(之前说到底的1MB的block)来避免数据热点。
- 计算外推,支持remote compaction
Hailstorm文件系统特点
- 只支持了一部分必要的Posix FS接口。
- 本地保存文件metadata,避免中心化文件metadata管理。
- 因为LSM KV已经有journaling,Hailstorm没有继续journaling。
- 既然主要任务是compaction,可以使用很激进的prefetch策略。
- LSM的WAL还是在本地机器上的。
Hailstorm存储架构
- 池化的磁盘在同一个机架,延时比较短(几us),对比存算一体,产生的延时可控。
- 在N台机器的集群种,块大小为B,数据offset I分布在机器 ceil((I / B) % N) 上。数据分布是静态的,没有考虑机器挂掉等情况。
- flatten目录树结构,每个文件有个uuid
- Hailstorm的client自己保存文件的uuid和文件到block的映射,以及其他文件元信息。
- 用了伪随机和batch sampling(没看懂)来避免server上的热点/skew。
- 虽然数据以block存取,为了优化读,读会以更小的力度来进行(避免每次读1MB),一次降低延时。
- 大部分请求异步,除了上层用fsync的时候。
- 支持RAID防丢数据。
Hailstorm计算外放
- Hailstorm在每个client上加了个agent,用来统计资源(CPU and/or memory)利用状态。
- 当agent发现本地资源过载,会停止正在进行的compaction,联系其他client代理完成。并提供必要信息比如文件元信息等。目标client起一个新的LSM(这个不清楚具体怎么做的)来专门做compaction。完成之后返回compact之后新生成的文件的元信息给源client。
- 使用EMA(exponential moving average移动窗口平均)计算per-node参数 a(大小在0-1之间) 来评估资源利用状态,并于其他机器进行相关信息的同步。当发现一台机器 a < threshold。就找到最新 a 的机器,将compaction任务发送过去。如果要禁止remote compaction就设置threshold为1。
实现细节
- 1,000 lines of C++ code(比我预想的少好多)实现Hailstorm,是同Fuse挂载进行服务(据说也可以用Parallel NFS,这个没了解)。
- 2,000 lines of Scala code实现distribution(?),client-server通信,agents。
- 使用Akka toolkit(也没有接触过,看上去是个类似于RPC的东西)来实现高性能并发和分布式。
- 对RocksDB更改只有几十行。
- 关于1MB,实验表明100 KB to 4 MB性能差不多,使用1MB是为了在多次FUSE延时和单次Remote访问延时之间的性能平衡。之前提到的为了读优化,读会有更小的粒度,实验采用的是64 KB。
实验结果
Hightlight一下Hailstorm的性能(MongoDB)
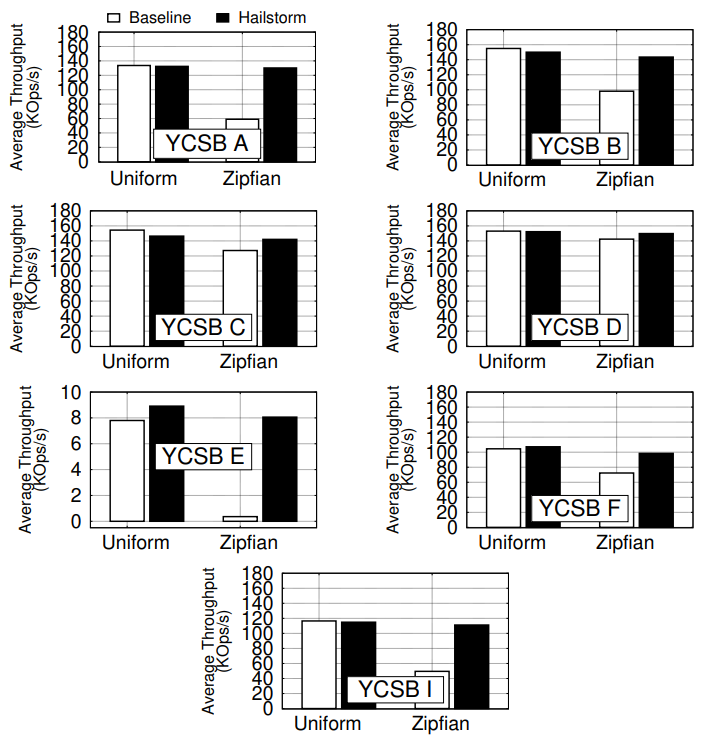
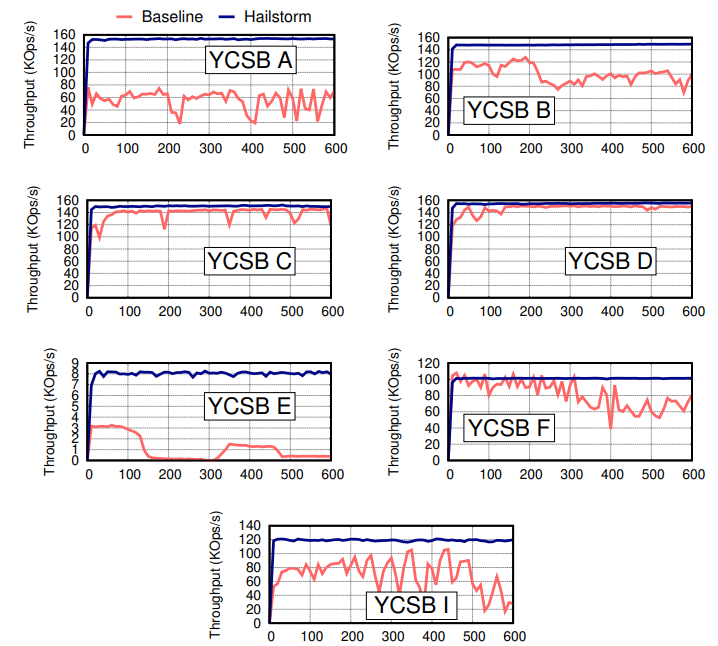
- 在各个测试集(不同测试集的请求类型和比例不同)里,Key均匀分布的请求模式下,Hailstorm吞吐基本和baseline(shared-nothing)打平,这意味着性能损耗不大(主要是网络和FUSE上的损耗)。
- 对于写密集请求(YCSB A、F、I),在ZipFian分布下,Hailstorm的吞吐比baseline有明先提高,池化存储和remote compaction都是原因。
- 对于读密集请求(YCSB B、C、D),在ZipFian分布下,Hailstorm的吞吐比baseline有明先提高,主要是因为池化存储分摊了读的压力,相当于读带宽高。
- 对于scan密集请求(YCSB E),在ZipFian分布下,Hailstorm的吞吐比baseline有明先提高,这个就是remote compaction的功劳了。
- 同时,在ZipFion分布下,Hailstorm的吞吐抖动很小,基本不变,但是baseline上可以看到清晰的上下波动。
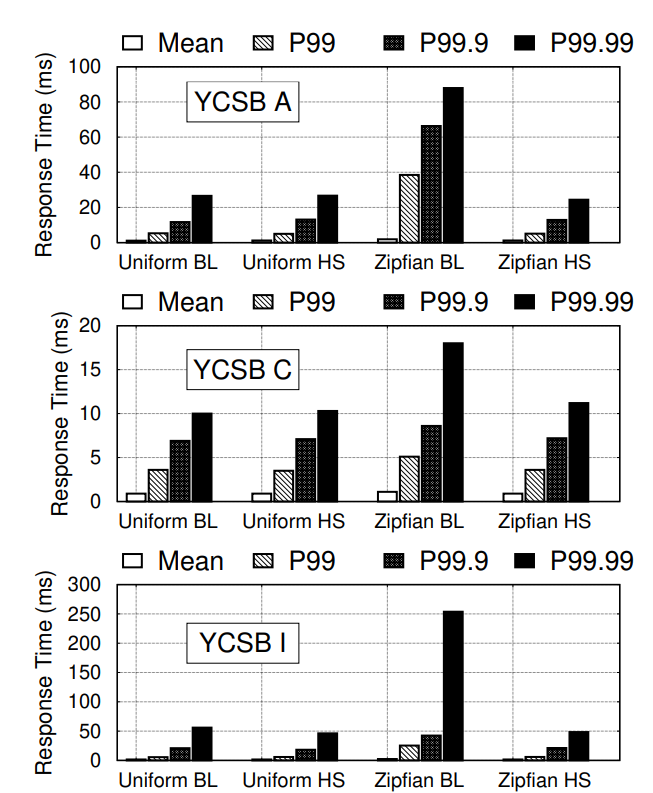
- 在各个测试集中,对比baseline均匀分布延时基本没有提高(包括99.9%),ZipFian分布时延时和尾延明显降低。
- 在数据规模量大了之后,即使是均匀分布,baseline同样会有吞吐的性能抖动,但是Hailstorm不会,因为compaction得到了和合理的分布。
关于resharding

- 能看到明显reshard对mongodb有提升,尤其是skew的时候。
- 在Hailstorm实验中,开了reshard反而更慢,原因是reshard需要解决的热点问题由池化存储解决,再进行reshard只会带来额外的IO损耗。所以上面实验中,hailstorm版的mongodb都是关闭了resharding的。
TiDB性能测试
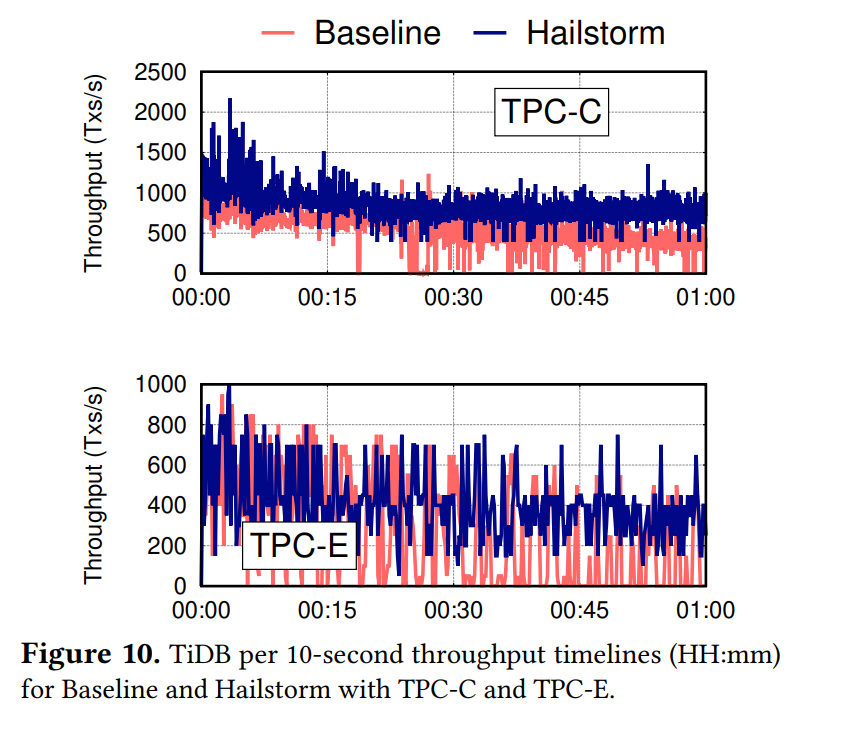
吞吐提升也不错。
Hailstorm和HDFS对比
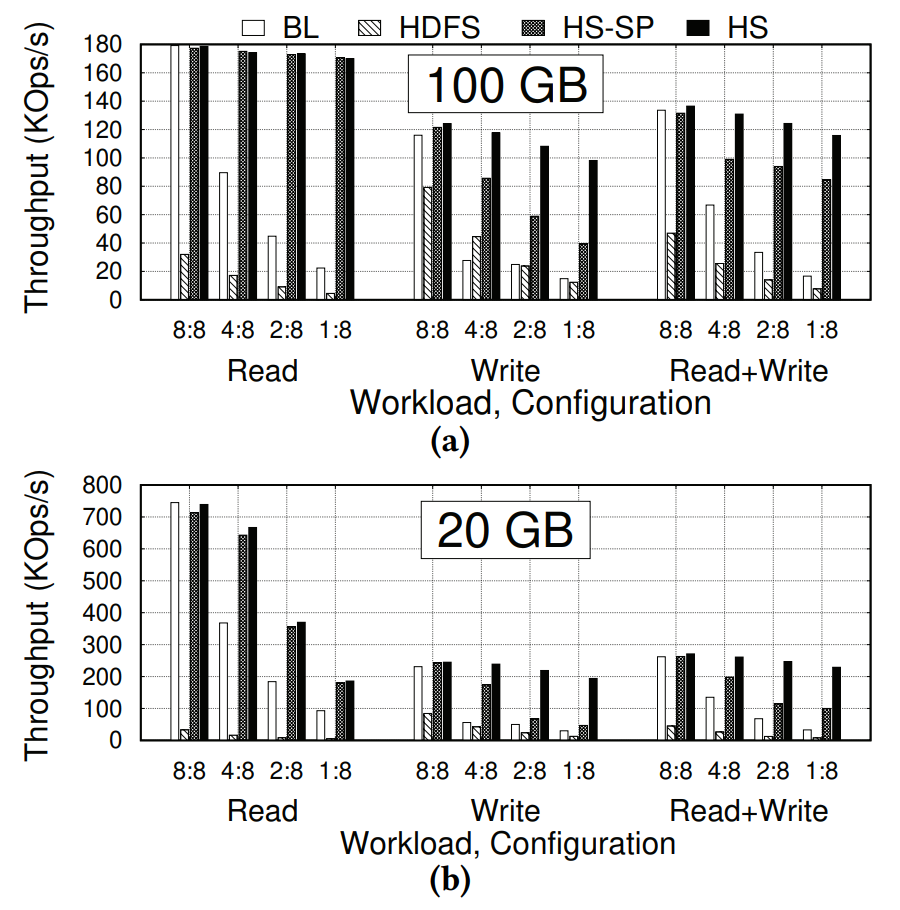
图中 i: 8 表示 i 个机器在服务请求,8 - i 个机器是idle的。
作者自己做了个小benchmark,对比了rocksdb-on-HDFS(不进行任何备份)和rocksdb-on-hailstorm,明显吞吐更高。这解释了为啥不用常见开源系统,需要专门设计一个。
HDFS慢的原因:
- 去NameNode读元数据
- 每次读写一个block
- 写倾向于写本地磁盘(为了locality)
有个有趣的点值得关注下:
- 对于Read-intensive的请求,当严重skew的时候,Hailstrom吞吐提升有限。调查发现是CPU成了瓶颈,大部分时间花在在内存里面二分查找。
可以用在B-Tree上吗
- B-Tree没有Compaction,不过作者任务B-Tree也有garbage collection这样的background task,也可以用来balance CPU。
- 作者试着不开computation offloading(不开remote compaction),在读场景优化有限,因为是CPU-bound。在写的场景和Scan的场景性能很好,因为池化存储分摊了I/O带宽。
总结
进步意义
- 把Remote Compaction这件事情落到了纸上并做了实验验证。
- 用一个阉割版posix文件系统,在rocksdb下面做了一层sharding,以两层sharding实现更好的load balance。还能基于此做compaction,挺巧妙的。阉割版也避免了实现的复杂性和复杂协议带来的性能损失。
- 架构上看已经和cloud-native有一些异曲同工之妙了。不过没有把所有的能力都下推到底层,在上层保留了容灾备份等能力。
- 做了比较完善的实验和各种角度的分析,各种替代选择几乎都提到了。
局限
- 所谓的解决skew的方法,其实和论文里面提到的Two-level sharding本质上差不多,没有太多新意。更有趣的可能还是Remote Compaction。
- Hailstorm作为一个文件系统有点简陋,没有考虑很多分布式文件系统该有的能力,比如语义完整性,备份(Hailstorm架构通过上层数据库层直接对shard备份),高可用等能力。甚至client或者server挂了数据就丢了,不过支持了RAID(氪金手段。。。测试性能的时候估计没开)可以缓解。如果一个server出问题,是全局所有sstable都丢失数据,这种不安全可能会是企业的选择。
- 文中的系统是建立在单个rack上的。如果为了实现高可用(比如两地三中心),需要每个rack做一个group,内部做balance,但是这个group也会发生skew的情况。如果跨rack,网络延时可以忽略这个前提又不成了(也许单个机房内做group,group内的延时也可以接受?需要对比两种延时验证下)。Locality的问题可能其实没有解决,只是一定程度上掩盖住了。
- TiDB的吞吐看上去并没有很稳定,似乎没有进一步分析。
- 作者如果试试在对比rocksdb-on-HDFS和ocksdb-on-HDFS-with-remote-compaction就更好了。可以进一步证明computation offloading的能力。估计会有人会想了解一下这种方案的性能。
