前言:这个论文是在字节时候的隔壁组发的论文,他们主要是做一些创新型的DB的组件。团队的班底来自字节收购的TerarkDB。关注到论文主要是因为在知乎上看到一些“争论”。其中也提到了我老板的Hailstorm,算是对remote compaction的进一步延伸。加上我对TerarkDB和FaaS也有一些兴趣,就拿来看看。
TL:DR版
论文把LSM的Compaction放到了FaaS平台上做,利用FaaS了的scalability。关注性能,性能的稳定性和弹性(scalability)。
背景
LSM的compaction导致性能spike。
论文主要做的:
- FaaS Compaction
- 为了防止大量数据的延时,提出了parallel slight compaction。通过把大的compaction任务分成小块,降低timeout风险。
RocksDB中有rate-limiter用来监控flush和compaction占用的I/O带宽,但是实际使用中,rate-limiter的阈值很难设定。
TerarkDB:
- 更少磁盘占用和更快的性能
- TerarkZipTable(类似于SSTable)和RocksDB结合
- 优势(TerarkZipTable带来的):
- 随机读更快
- 更高压缩率
- 更低内存占用
TerarkZipTable替换SSTable:
- 基于SSTable加入CO-Index and PA-Zip
- CO-Index (Compressed Ordered Index)
- Nest Succinct Trie,压缩Key集合
- 可以直接在压缩数据上搜索
- 把Key映射成integer ID
- PA-Zip (Point Accessible Zip)
- 压缩value集合
- can directly extract a single value based on the integer ID
PatriciaMemTable替换MemTable:
- Dynamic Patricia Trie
- 基于Copy-On-Write思想
FaaS:
- FaaS平台支持自动扩容,计算workload大,自动使用更多的FaaS instances
- 不会影响本地性能
设计
架构
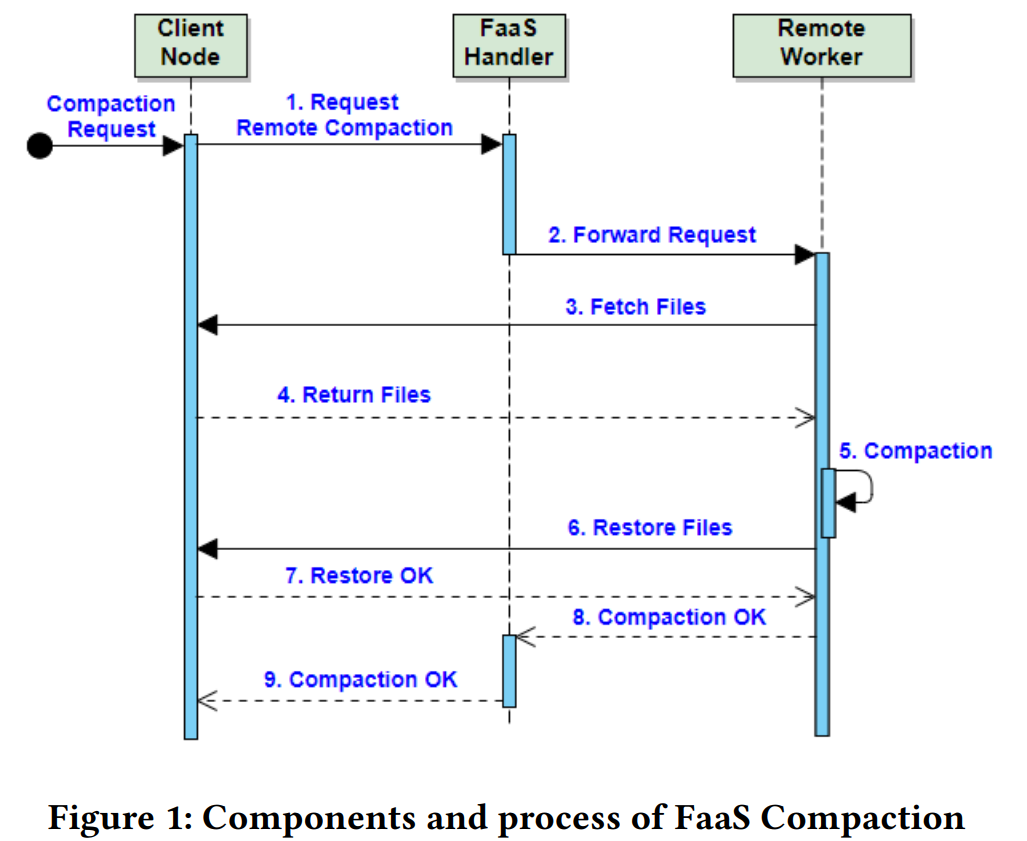
基本架构如上图
Client Node:
- 跑着TerarkDB
- 也有一个进程模拟用户给TerarkDB发读写请求
- 决定具体如何执行compaction(应该是跑着TerarkDB的进程来决定?):
- 有三种,本地,offload compaction,FaaS上
- Client上有用来和远程交互的接口 。可以用来发起请求和交换sstable。(应该也是跑着TerarkDB的进程?)
- 负责分割大块的compaction。(应该也是跑着TerarkDB的进程?)
FaaS Handler
- 应该已经是FaaS平台的一部分了。
- 类似于scheduler,转发请求到真正的worker上。
- 当初始化handler时,总会同时初始化一个remote worker,避免无worker可用(这个应该是FaaS来完成)
- 如果没有handler可用,会自动初始化一个handler和worker。(没有说谁来初始化,大概是FaaS平台吧)
Remote Worker:
- 同样会跑一个TerarkDB专门用来做compaction
- 作为一个FaaS instance来实现,可以自动扩缩
如何实现offloading compaction
- 使用固定数量的worker
如何实现FaaS compaction
- 把handler和worker都实现成FaaS Instances
算法
算法很直观,值得关注的主要是用来做compaction的参数:
- the set of file names
- key range of compaction
整个发请求,取sstable,compact,回传sstable的过程都在一个TCP connection发生。
为了避免大块compaction任务造成timeout,将任务分割。如果还是Timeout或者其他因素返回不是OK,client node进行本地compaction。
优势
- 自动scale
- 系统性能稳定,compaction的性能也稳定
- 高效,parallel slight compaction scheme,parallel 提升效率,slight 降低延时
Parallel Slight Compaction
不分割的问题
- 在作者使用的FaaS机器上,HTTP最长也就15min
- FaaS冷启动,指的是FaaS handler,如果长时间没有请求FaaS平台会回收资源。
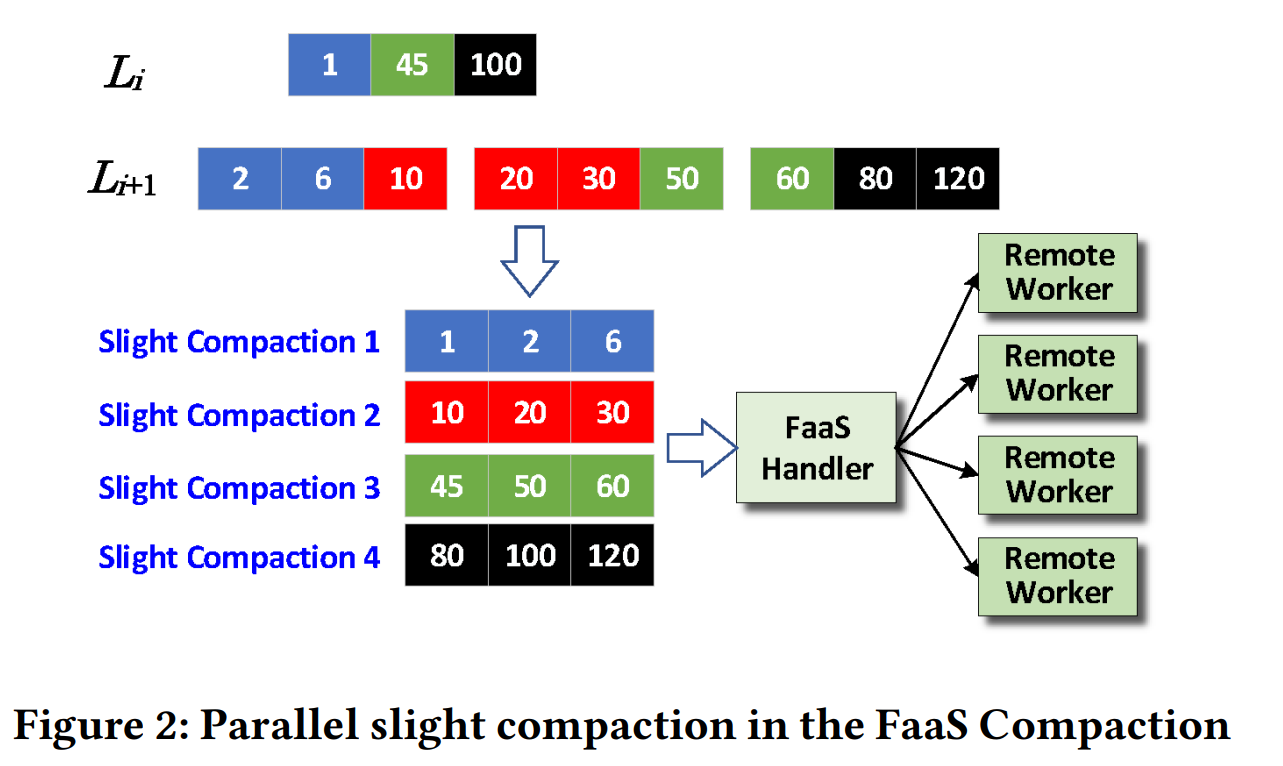
具体细节:
- 根据range分割而不是文件,让每个子任务(不仅单次compaction的子任务,而是所有compaction的子任务)有同样size的sstable。减少straggling
- 每个Remote worker负责一个slight compaction任务。
- 自动scaling体现在,当compaction任务多的时候自动分割成很多slight compaction,然后利用FaaS自动起很多对应数量的worker。如果compaction任务量不大,对应的slight compaction少,worker也就少。
- 没看明白怎么解决冷启动的,感觉是通过把HTTP timeout时间设置的很高,计算完了不结束connection,一直等新请求来实现的。当进行任务分块,每个分块很小,所以空等的时间更长,就可以一定程度避免冷启动。
实验
- 能观察到比较有趣的点是offloading compaction在任务前期还比较稳定,长期来看,由于数据量大了,最终会触及固定台机器的CPU-bound,导致前台等待,最终影响服务的QPS。
总结
局限
- 想通过这篇论文了解TerarkDB和FaaS是我naive了。。。TerarkDB的设计也有一些缺陷详细内容可以参看TerarkDB作者的分享。
- 用FaaS来做Compaction,相对来说没有太多实际应用价值。引入了新的依赖,而且大部分非大厂LSM用户也没有(免费的)FaaS平台能用。
- 冷启动的部分不怎么清楚和make sense。
对比下hailstorm
- hailstorm是在尝试压榨资源。FaaS Compaction继承了字节财大气粗的特色,发现计算瓶颈了就找另外一波资源来做。
- hailstorm针对对池化存储的访问延时,设置了同一个rack的限制。FaaS Compaction看上去没有太考虑这件事情,慢慢传,反正进行了分割和并行加速。不过FaaS Compaction对于源机器会造成额外的网络I/O开销,hailstorm不会。
